[python 활용하기#11] pandas 데이터 다루기 (데이터프레임)
안녕하세요. 심심한 코딩쟁이입니다.
오늘은 파이썬의 pandas를 활용해 기초적인 데이터 다루는 방법에 대해 알아보려합니다.
pandas는 Python Data Analysis Library를 조합해 만들어진 이름입니다.
파이썬에서 데이터를 분석하기 위해서는 거의 필수적인 존재입니다.
함께 살펴보시죠.

판다스 Pandas
공공기관의 데이터를 받아서 작업할 때나 직장에서 각종 데이터들을 정리하다보면 방대한 데이터 양으로 인해
수동으로 처리하기에는 어려운 상황이 생기기 마련입니다.
이럴 때 판다스를 사용하면 원하는 작업을 보다 쉽게 진행할 수 있게 됩니다.
판다스에서는 데이터프레임 이라는 것을 사용해 데이터를 다루는데
이것은 통계 분석에서 많이 사용되는 R의 데이터프레임과 비슷하게 만들어진 것으로
수집한 데이터의 전처리에 용이하고 표 형태로 표현도 가능하며, 다양한 방법으로 데이터를 조작할 수 있습니다.
우선 판다스를 설치해볼까요?
새로운 파이썬 패키지를 설치하기전에 항상 pip 업데이트하는 것을 습관화합시다.
윈도우 사용자
python -m pip install --upgrade pip
리눅스 사용자
pip --upgrade pip
업데이트 완료 후 판다스 설치 명령어를 입력합니다.
pip install pandas

설치가 완료되면 파이썬을 실행해 판다스를 import 해보는 것으로 설치가 제대로 되었는지 확인해봅니다.

여기까지 문제 없이 잘 진행되었다면 이제 판다스를 사용하러 가보실까요?
데이터프레임
판다스에서 데이터를 다룰 때 사용하는 것이 데이터프레임이라고 말씀드렸는데 이제 직접 만들어보겠습니다.
데이터프레임으로 만들 표를 보여드리겠습니다.
각 학생의 회차 별 시험 점수를 보여주는 표입니다.
| Amy | David | Irene | |
| 1 | 90 | 90 | 90 |
| 2 | 80 | 100 | 90 |
| 3 | 70 | 100 | 100 |
위 표를 데이터프레임으로 만들기 위해서는 우선 데이터프레임의 구조를 알아야겠죠?
표를 보면서 데이터프레임의 구조를 설명해드리겠습니다.
Amy, David, Irene이 위치한 곳을 데이터프레임의 columns 라고 합니다.
1, 2, 3 이 위치한 곳을 데이터프레임의 index 라고 합니다.
columns 과 index는 데이터프레임에서 데이터들을 구분하기 위해 필요한 기준이라고 보시면 됩니다.
그외 나머지 칸에 존재하는 데이터들은 데이터프레임의 내용이라고 생각하시면 됩니다.
그럼 코드를 사용해 데이터프레임을 만들어보시죠.
import pandas as pd
col = ['Amy', 'David', 'Irene']
ind = [1, 2, 3]
data = [[90, 90, 90], [80, 100, 90], [70, 100, 100]]
dataframe = pd.DataFrame(data, index = ind, columns = col)
print(dataframe)
###############
# 출력 결과
###############
Amy David Irene
1 90 90 90
2 80 100 90
3 70 100 100데이터프레임 데이터를 파일로 저장
위에서 정의한 데이터프레임을 파일로 저장할 때 csv 또는 xlsx 파일로 저장이 가능합니다.
dataframe.to_csv('test.csv', index = False)
dataframe.to_excel('test.xlsx', index = False)
앞에서 살펴본 코드뒤에 이렇게 붙여 넣기만하면 파일안에 데이터프레임의 내용이 생성됩니다.
index = False로 설정하면 1, 2, 3 이란 데이터로 존재하던 인덱스가 파일에서는 표기되지않습니다.
아래 그림은 파일에 저장된 데이터프레임의 모습입니다.
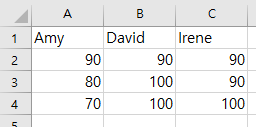
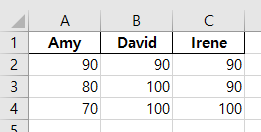
두 파일 모두 데이터프레임의 인덱스로 쓰인 1, 2, 3이 보이지 않습니다.
여기까지 Pandas 데이터 다루기 데이터프레임에 대한 내용이었습니다.
아주 기초적인 부분만 살펴보았기 때문에 추후에 더 유용한 내용을 가지고 포스팅 하겠습니다.
궁금하신 점이나 도움이 필요한 부분이 있다면 댓글로 남겨주세요.
감사합니다.
'programming > python' 카테고리의 다른 글
| [python 활용하기#13] Pandas 데이터프레임 병합하기(merge) (0) | 2023.03.28 |
|---|---|
| [python 활용하기#12] Pandas 여러 시트 통합 후 피벗테이블 만들기 (0) | 2023.03.23 |
| [python 활용하기 #10] 행렬 연산 방법 (사칙연산, 행렬 곱, 내적, 외적) (0) | 2023.03.13 |
| [python 활용하기#9] 파이썬 numpy 설치하기 (0) | 2023.03.12 |
| [python 활용하기 #8] openpyxl 글꼴 다루기 - 파이썬 엑셀 (0) | 2023.03.11 |



